🤖 O Que São Transformers?
Entendendo o Artigo “Attention is All You Need”
Se você já ouviu falar em ChatGPT, Bard, Gemini ou LLMs, então você está vendo os resultados do paper “Attention is All You Need” — o artigo que revolucionou o campo da inteligência artificial com o conceito de Transformers.
Neste post, vou explicar de forma simples o que são Transformers e por que eles mudaram tudo.
📖 Contexto: Antes do Transformer
Antes de 2017, a maioria dos modelos de linguagem usava RNNs (Redes Recorrentes) ou LSTMs, que leem uma sequência palavra por palavra. Isso gerava limitações, como:
• Dificuldade de paralelização
• Perda de contexto em sequências longas
• Treinamento mais lento
⚡ A Inovação: Self-Attention
O artigo do Google propôs um modelo que não depende de recorrência. Em vez disso, ele usa um mecanismo chamado Self-Attention, que permite que o modelo preste atenção a todas as palavras da frase ao mesmo tempo, ponderando a importância de cada uma.
Exemplo prático:
Na frase:“O gato viu o cachorro na rua porque ele estava latindo.”
Com self-attention, o modelo pode entender que “ele” provavelmente se refere a “o cachorro”, e não “o gato”.
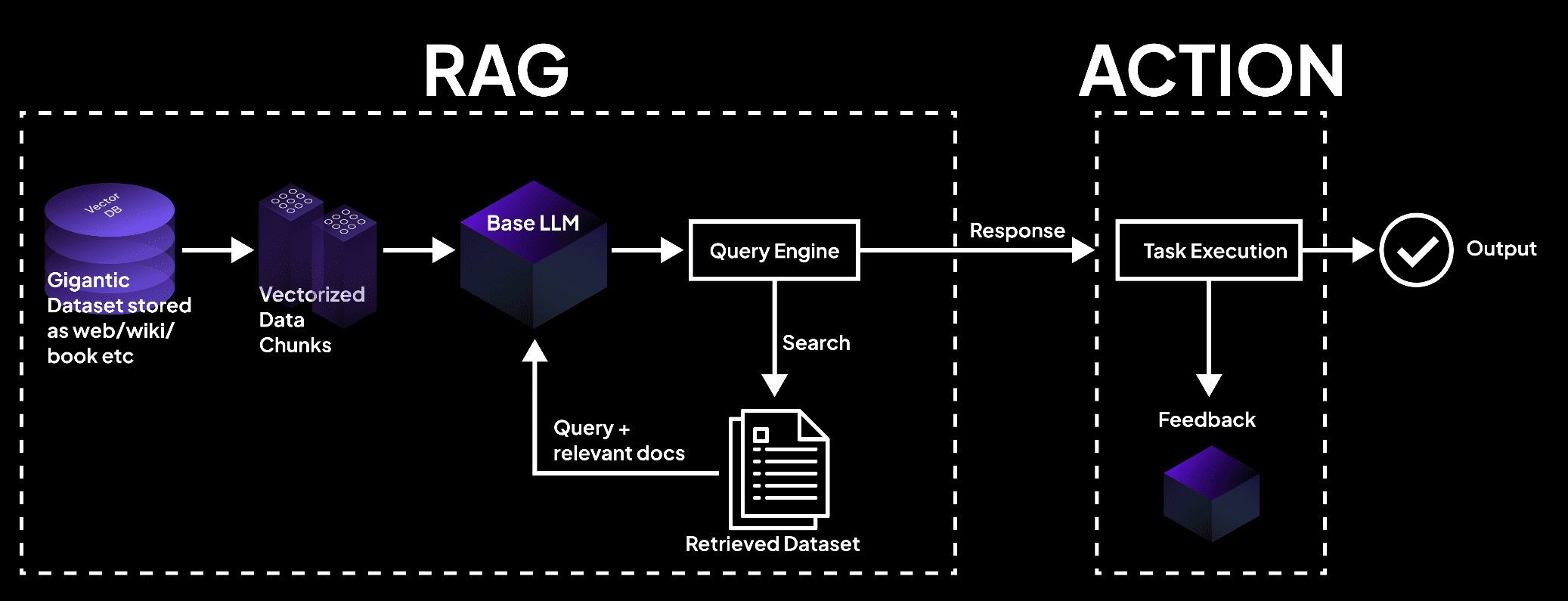
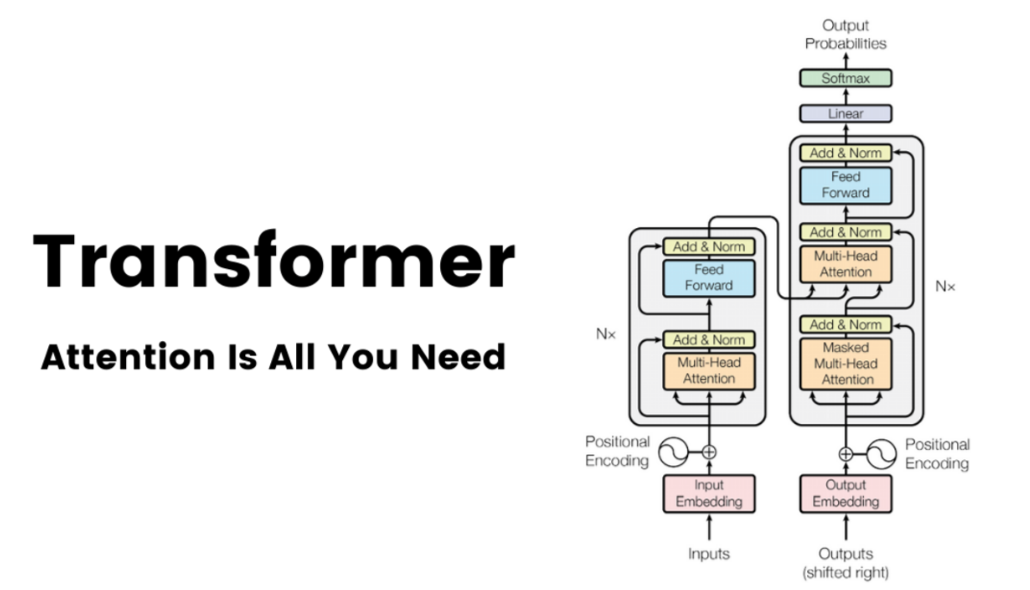
🧠 O Que é um Transformer?
Um Transformer é um modelo de deep learning composto por camadas de atenção e camadas feedforward, que processam entradas de texto em paralelo e com maior capacidade de entender relações complexas.
Estrutura básica:
• Encoder: entende o contexto da entrada
• Decoder: gera a saída com base nesse contexto
(LLMs como ChatGPT usam só o decoder; BERT usa só o encoder.)
🧩 Por que foi revolucionário?
✅ Treinamento paralelo (mais rápido que RNNs)
✅ Escalável — funciona melhor quanto mais dados e camadas
✅ Contexto global — entende relações entre palavras distantes
✅ Versátil — serve pra tradução, resumo, geração de texto, código, imagem, áudio...
🔬 Um detalhe técnico: “Attention” explicada de forma simples
O modelo calcula algo como:
mathematica
CopiarEditar
Atenção(Q, K, V) = softmax(Q × Kᵀ / √dₖ) × V
• Q = Query (o que estou tentando entender)
• K = Key (o que tem disponível)
• V = Value (o que preciso da informação)
Isso permite que o modelo pese quais partes do texto são mais importantes para a tarefa.
💥 Impacto do Paper
O artigo “Attention is All You Need” foi publicado em 2017 por pesquisadores do Google e se tornou uma das publicações mais citadas da história.
Desde então, surgiram modelos como:
• BERT (2018)
• GPT (1, 2, 3, 4)
• T5
• Gemini (ex-Bard)
• Claude
• Mistral, LLaMA, Falcon...
🚀 ConclusãoO Transformer é o coração das IAs modernas.
Sem ele, a revolução atual em IA generativa provavelmente não teria acontecido tão rápido — e tão bem. Se você desenvolve ou se interessa por IA, esse é um conceito essencial para o seu vocabulário técnico.